Zero to Not Hero: LLMs

This summer when I asked at lunch what a neuron is, no one was able to explain. Surprisingly, people just said it’s just math; no one understood why it matters and how it affects the ML model.
But even to me, ML was a black box, let alone a neuron. At the same time LLMs were making noise, the rise of MCP, AI agents, cloud code, and Cursor was making software engineers product managers on steroids.
This just led me to think, what are LLMs? How do they work? What is the magic behind this tech, which is generating billions of dollars, and people are getting hired for hundreds of millions?
Just like any other concept, I went to YouTube and started watching one playlist on how LLMs work and watched a bunch of talks, but none made sense. I used to ask this stupid question: why do we even need activation functions, why do we have so many activation functions, and who decides how many layers and the width and depth of the layers?
I realized I lack the basics of ML, as I never studied CS in uni.
But learning intro to ML on Coursera is too boring; math is not something I fancy. I kept looking for shortcuts but got none.
I do like the engineering-first mindset: get things running quickly without going into a rabbit hole of stuff I will never use. Fortunately, I gave a shot to Andrej Karpathy’s zero to hero on deep learning. As soon as I went through some of it, Deep Learning (DL) made sense to me. Note at this point I still don’t know ML beyond the DL. I sent the below email to my friend who is kinda good at DL.

I finally understood what a neuron is, how training works, forward pass, backward pass, gradients, and writing your own autograd.
This series takes you to the GPT implementation, but then for me it was too much to unpack in the video and then implement. The video was 4 hours long, and going back and forth of the video is literally a nightmare. I almost gave up learning LLMs.
At this point I knew the intro to PyTorch, building a simple DL model in PyTorch, training it, validating it, and what validation loss, training loss, and no_grad are. Pretty basic fundamentals of the DL model cycle.
But my initial curiosity about how LLMs work was still not satisfied. To this date I have never read any book to learn any concept after my undergrad. Everything I learned was from online blogs, YouTube, or on the job. So the idea was the book was alien but untried.
But Paul Graham:()()
But as a wannabe high-agency guy, I ordered the LLM from scratch book. I read half of it on the flight to India and half while my mom was convincing me to get married.
But just like Karpathy’s lecture, this has many details, but this time I had control over the pace of content. It felt like a text version of Karpathy’s lectures. The book assumes you know the basics of DL :), which to me was tough by Karpathy.
As the book proceeded, I started implementing the author’s model, eventually loading the model from Hugging Face. My latest attempt was training GPT-2 on the hindi text, where my dataset name was “durga-ma-mandir.txt.” :P
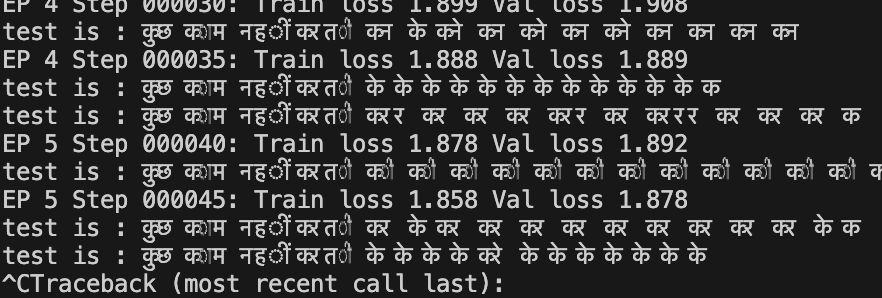
Unfortunately I am facing the problem of how to scale the model to my local machine and also use the right tokenization strategy for Hindi + GPT2. But that’s WIP; you can find any progress on GitHub at https://github.com/darsh7807/learn-llm-with-me
This is roughly 2 months of time I spent, and in this time, from not knowing what a neuron is, I am making sense of transformer architecture and comprehending training.
By no means am I am expert, but here is what I learned.
Learning from builders ’s mindset: The key principle I was using was not getting into theory but knowing what I should know to build a simple LLM. I still don’t know ML beyond DL.
Fundamentals compound: In summer 2025, when I got to know about vLLM, I didn’t even understand what it was doing or how it was making LLM faster. But after going over these fundamentals about DL and transformers, it makes more sense.
Model architecture: Stop and ask Gemini to summarize this video. It’s funny to see how an entire industry converges after doing so many experiments on the architecture. It gives me the impression a lot of the knowledge is empirical rather than derived. But you will also see how model architectures are optimized for systems (infra) of training and inference.
LLMs: Research is funny; quite a good portion of research is based on taking the existing work and then changing it with your agenda. You learn from previous work and try to fit in your problem statement. If you follow Karpathy’s video, he refers to so many papers and how modern LLMs evolved from previous work with some new techniques. It leads to a compounding effect, and you get really amazing results. Which to me, most of the LLM evolution is currently experimenting with models, optimizing the systems, and adding new research to production grade. And it seems exciting; like a Netflix series, you keep seeing new outcomes.
DL: This was the most fun part. Learning the basics of PyTorch, forward pass, backward pass, gradient vanishing/spiking, activations, parallel vs. linear layers, FLOPs, embeddings, fine-tuning, and what not. Shows there are so many things to unpack.
What’s next:
The LLM space is evolving with both model training and inference. Systems become the most challenging part and have a high ROI wrt invested time. From my limited understanding, most of the LLM research seems to be exploratory engineering, but unfortunately, LLMs need a good amount of computing, and doing so seems quite hard as a side project. But what is not high-scale is the system side of LLMs, where I still have a lot of space to learn and implement fundamentals.
Jokes apart, can you give me the resources you used to understand this stuff? I want to start somewhere, maybe your resources can help.
Jokes apart, can you give me the resources you used to understand this stuff? I want to start somewhere, maybe your resources can help.